


· 11 min de leitura
A LLM Wiki do Karpathy, mas para a tua campanha de D&D (e já está em produção)
Há três semanas Andrej Karpathy publicou um gist que acumulou milhares de estrelas: para de usar LLMs como motores de busca sobre os teus documentos e começa a usá-los como engenheiros de conhecimento que compilam uma wiki viva. Depois Garry Tan lançou o GBrain — um cérebro que não só recorda, mas age. O mundo IA decidiu que a memória era a próxima grande batalha.
Passámos um ano a construir a versão mais complicada possível desse problema, e não é uma base de conhecimento empresarial. É um jogo. Porque um Mestre IA tem de recordar a tua história, escrevê-la sem se contradizer e eventualmente agir sobre ela — as três camadas que toda a gente está a teorizar, a correr contra uma história que pune cada erro.
Por que razão a IA esquece a tua campanha?
A janela de contexto não é memória. É um quadro branco que se apaga depois de cada sessão. Um modelo pode lidar com um milhão de tokens, mas a qualidade começa a degradar-se muito antes disso, e quando a sessão termina, tudo desaparece. A conversa seguinte começa do zero.
Num chatbot isso é irritante. Numa campanha de RPG é fatal. Passas três sessões a construir uma rivalidade com uma contrabandista chamada Elara. Poupas-lhe a vida numa cripta. Duas semanas depois o Mestre apresenta-a de novo — como um homem, de outra cidade, que nunca te conheceu. A ilusão quebra. A história em que estavas investido deixa de ser tua. Se já jogaste com um LLM simples, conheces exatamente esse momento: o NPC morto que continua a falar.
O RAG foi a primeira solução séria: converte os teus documentos em vetores, guarda-os e recupera os fragmentos relevantes no momento da consulta. Funciona — milhões de sistemas em produção usam-no. Mas tem um limite estrutural que um artigo de 2024 mapeou em sete pontos de falha. Três importam para um Mestre: o chunking divide uma personagem em fragmentos de modo que o modelo encontra um e perde o resto; a re-derivação faz com que cada turno comece do zero sem aprender nada; e a passividade significa que o sistema apenas responde, sem detetar que duas fontes se contradizem.
Três formas de uma IA recordar: recuperar, compilar, agir
O debate atual alinha três arquiteturas. Apresentam-se como rivais. Não são — são três camadas do mesmo stack.
- Recuperar (RAG) — encontra conteúdo relevante à escala. Excelente em amplitude, cego em profundidade; relê os mesmos livros em cada exame e nunca aprende a matéria.
- Compilar (a LLM wiki) — a ideia de Karpathy: compila as fontes uma vez numa wiki persistente e interligada. O conhecimento acumula-se; simplesmente não escala a milhões de documentos.
- Agir (competências autónomas) — o GBrain de Garry Tan: conhecimento que não fica parado mas dispara ações, corre com um calendário, trabalha enquanto dormes. Poderoso, e um compromisso de engenharia sério.
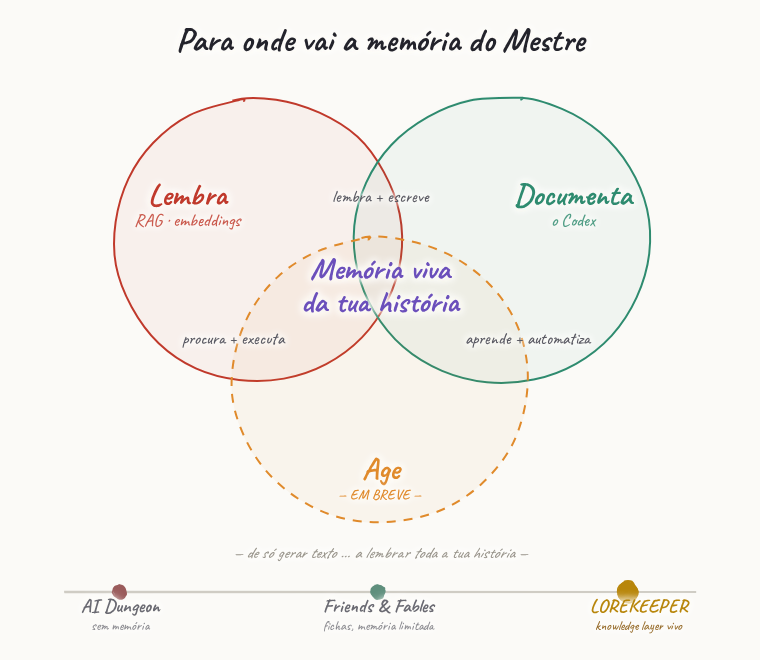
A pergunta certa não é “qual ganha.” É qual é o trabalho do teu agente? O trabalho de um Mestre é os três em simultâneo — por isso é um caso de teste tão brutal. É aqui que estamos de facto.
Recuperar: RAG sobre a tua campanha
A camada base é RAG real. Cada artigo do Codex da tua campanha é convertido num vetor e guardado com pgvector no Postgres. Quando o Mestre precisa de algo que as pesquisas estruturadas não cobrem, executa uma pesquisa semântica sobre esses embeddings e recupera as passagens mais próximas.
Esta é a parte pouco glamorosa mas essencial. Escala, é rápida o suficiente para um turno em direto e é o fallback quando o grafo ainda não conhece a resposta. Mas por si só tem exatamente a fraqueza que Karpathy aponta: recupera, nunca acumula. Por isso não ficamos por aqui.
Compilar: o Codex é a LLM wiki do Karpathy
O Codex é a LLM wiki do Karpathy. Lançámo-lo para RPG de mesa em vez de artigos de investigação. As mesmas três camadas que ele descreve:
- Fontes imutáveis — a tua partida real. A transcrição do que aconteceu à mesa. O modelo lê-a mas nunca a reescreve.
- A wiki — o Codex: páginas de entidades escritas pelo LLM para cada NPC, local, missão e fio narrativo, com resumos, estado e referências cruzadas. O modelo é dono desta camada.
- O esquema — as regras sobre como a wiki é mantida: o que conta como NPC, como se formam os backlinks, o que é uma contradição.
E acumula-se como Karpathy descreve. Quando uma cena termina, o Mestre não escreve apenas um resumo — lê os eventos novos contra o Codex existente e atualiza cada página que tocam: novas referências cruzadas, estado atualizado, uma nova entrada na linha do tempo. Uma entrada literalmente diz “O DM mantém esta entrada.” A wiki enriquece-se quanto mais jogas.
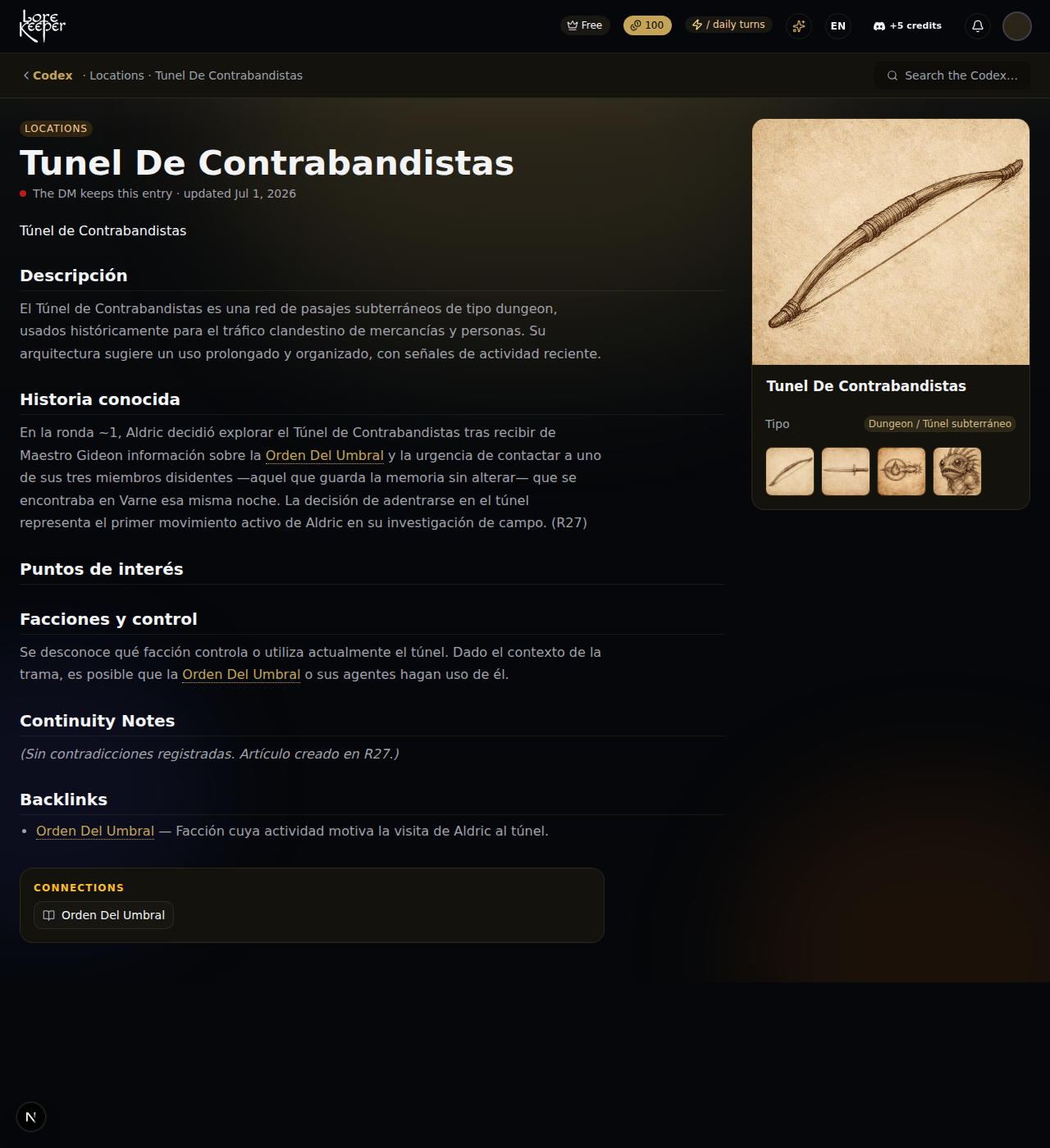
O resultado foi lançado esta semana: o Mestre lê agora o seu próprio Codex em cada turno. Não despeja a wiki inteira no contexto — encaminha para as entidades que importam na cena atual, carrega as suas páginas mais um salto de backlinks, e injeta um bloco de memória compacto. Isso é a interseção recuperar + compilar que toda a indústria desenha num quadro branco, a correr numa partida real.
O problema que ninguém menciona: coerência, não memória
Os ensaios sobre “o RAG morreu” saltam a metade difícil. Numa história, recordar é a metade fácil. A metade difícil é não te contradizeres. Uma wiki que se compila sozinha irá acumular as suas próprias alucinações — um detalhe errado é referenciado em três páginas e torna-se cânone. O gist do Karpathy tem 200 linhas elegantes; em produção, o lint e a verificação são 80% do trabalho real.
Portanto a engenharia interessante não é o passo de compilação, mas as salvaguardas. O Codex separa o que um jogador pode ver dos segredos só para o DM, de modo que a memória que o Mestre lê pode incluir o twist sem o revelar nunca à mesa. E não confiamos em nada disto ao acaso — corremos evals. Com o bloco de memória ativo, o Mestre usa aproximadamente três vezes mais factos canónicos por cena e nunca revelou um segredo em execuções repetidas; sem ele, inventou três origens mutuamente contraditórias para a mesma personagem. Essa diferença é o produto inteiro.
Agir: o que vem a seguir
A terceira camada é a parte honesta do roadmap. Hoje o Mestre já age através de ferramentas — lança dados, resolve combate mecânico, regista NPCs, controla relógios de pressão. Mas disparam de forma reativa, enquanto narra o teu turno. O que ainda não faz é o que o GBrain de Garry Tan faz: correr por conta própria.
A versão que queremos é um Mestre que mantém o mundo em movimento entre sessões — a avançar o esquema de um rival, a gastar o favor que um NPC te devia, a deixar que uma ameaça que ignoraste ganhe força — para que regresses a um mundo que viveu sem ti. Essa é a camada de ação, e é o honesto “em breve” no diagrama acima. A memória e a wiki são os pré-requisitos difíceis, e já existem.
Então qual é a arquitetura vencedora?
Nenhuma por si só. Da mesma forma que as bases de dados deixaram de ser “SQL ou NoSQL” e se tornaram sistemas híbridos, a memória em agentes está a convergir num único stack: recuperar à escala, compilar em conhecimento persistente, agir sobre ele de forma autónoma. As equipas que ainda perguntam qual escolher estão a fazer a pergunta errada.
Não começámos isto para provar uma tese sobre memória IA. Começámos para construir um Mestre que não se esquece da tua história. São o mesmo projeto. E o lugar menos indulgente para o testar não é uma wiki empresarial — é uma mesa de jogadores que vai notar no segundo em que o seu rival morto voltar a falar.
Perguntas frequentes
O que é uma LLM wiki?
Uma LLM wiki é um padrão de memória popularizado por Andrej Karpathy: em vez de recuperar fragmentos de documentos em bruto no momento da consulta (RAG), usas o modelo de linguagem para pré-compilar as tuas fontes numa wiki persistente e interligada de resumos, páginas de entidades e referências cruzadas. A síntese acontece uma vez; cada pergunta futura beneficia dela. O conhecimento acumula-se em vez de ser derivado de novo em cada consulta.
Como é que um Mestre IA recorda a tua história?
Um Mestre IA capaz não depende da janela de contexto, que é apagada entre sessões. O LoreKeeper escreve no Codex — uma wiki viva — cada NPC, local e pacto que o teu grupo descobre, e faz com que o Mestre leia esse Codex em cada turno. Assim recorda quem te deve um favor e o que juraste há três sessões, em vez de inventar uma nova versão.
O RAG morreu?
Não. O RAG não é rival de uma LLM wiki nem das competências autónomas — é uma camada. O RAG é a camada de recuperação que encontra conteúdo relevante à escala. Uma wiki é a camada de síntese que o compila em conhecimento persistente. As competências são a camada de ação. Os sistemas em produção combinam as três; o debate sobre qual "ganha" apresenta-as como rivais quando fazem parte do mesmo stack.
Qual é a diferença entre RAG e uma LLM wiki?
O RAG recupera e esquece: cada consulta relê os mesmos fragmentos e começa do zero. Uma LLM wiki compila uma vez e reutiliza: lê os eventos novos contra a wiki existente, atualiza cada página afetada e cria referências cruzadas. O RAG escala a milhões de documentos mas nunca aprende; uma wiki melhora com o tempo mas não escala a corpora enormes sem uma camada de recuperação em cima.
Pode um Mestre IA agir sozinho entre sessões?
Ainda não na maioria dos produtos, incluindo o LoreKeeper — as ferramentas do Mestre são reativas: disparam enquanto narra o teu turno. A próxima fronteira (o que Garry Tan chama GBrain com competências autónomas) é um mestre que avança os enredos dos NPCs, gera consequências e atualiza o mundo enquanto estás offline. Essa é a camada de ação, e está no roadmap.
Joga com um Mestre que recorda
O Codex escreve-se sozinho enquanto jogas, e o DM lê-o em cada turno. Começa uma campanha grátis — 100 rondas, sem cartão, a solo ou com até cinco amigos.
Jogar grátisGuias relacionados
O Que É um Mestre de RPG com IA
Guia completo: o que é, como funciona e por que está revolucionando os jogos de mesa.
Como Jogar RPG Online Sozinho com IA
Guia passo a passo da criação de personagem até a primeira aventura em solitário.
Os Melhores Mestres de RPG com IA em 2026
Comparação das melhores plataformas de RPG com IA em 2026, analisadas em detalhe.